
Most of what we are doing is not computational. We have been creating RNAi to inhibit our genes of interest. It’s tricky with drosophila: only a handful of the candidate genes are expressed in our cell line and only a subsection of that was capable of RNAi production. Despite this, we managed to produce 4 RNAi lines for these genes.
Author: Alex
Week 9: Cell tracking
So now we are in the experimental validation phase. This week, we ran a trial run of the cell tracking software, using newly cultured cells from a drosophila melanogaster, or fruit fly, line. These lines are suitable for validating that the genes are involved in cell motility due to the high degree of conservation between humans and fruit flies in basic cellular mechanisms.
Summer Week 8: Positive and Negative Sets
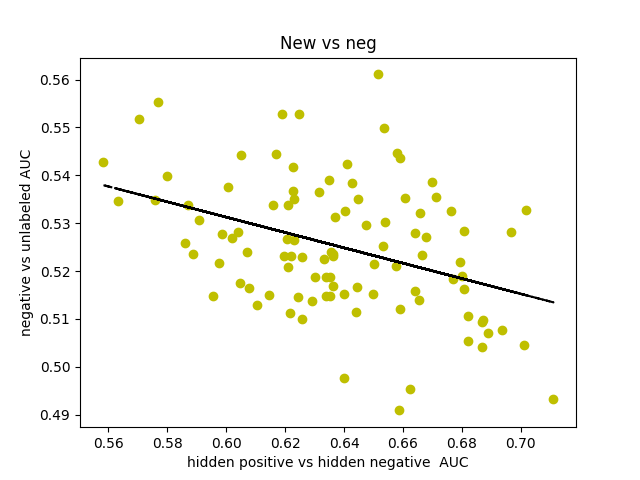
I was curious about what our AUC would look like if instead of comparing hidden positives to unlabeled, we compared hidden positives to hidden negatives, wondering if that would get us a more valid representation of the network’s ability to predict genes associated with schizophrenia. What if the unlabeled genes ranked above the hidden positives were simply actual centers of genetic perturbations in schizophrenia?
Oddly enough, the scores actually decreased from 0.65-0.70 to 0.60-0.65. I found that the AUCs for comparing hidden negatives to unlabeled nodes hovered around 0.53, meaning that the hidden negatives were ranked mostly in the top half of the list.
This somewhat makes sense though. The basis for the negative set is that they are genes in non-neurological diseases, but that doesn’t necessarily exclude them from being included in a more subtle, polygenic disorder that’s dependent on additive effects of hundreds of genetic perturbations. It also makes sense that genes involved in other diseases might have a slightly higher probability of being associated with some other disease.
I decided to make a new negative set. I started by gathering every single node in the 0.150 network. There is a resource called SZGR 2.0 (https://bioinfo.uth.edu/SZGR/) that collects all sorts of evidence for genes being associated with schizophrenia. Using this list, I excluded any gene that had any evidence for being associated with schizophrenia. I then took differential gene expression data from autism spectrum disorder, bipolar disorder, and major depressive disorder as well as schizophrenia (http://science.sciencemag.org/content/359/6376/693). If a gene was not differentially expressed in any of these diseases (FDR>0.5 for schizophrenia, FDR>0.2 for others) and was in the other list, I added that gene to my list of negatives, which was 1561 genes long. I found that this list, when hidden negatives were compared to unlabeled genes, had an AUC of about 0.44, which means that our negatives are finally oriented around schizophrenia rather than non-neurological diseases. I also found that the AUC for hidden positives vs hidden negatives spiked up to 0.75, meaning that our program is legitimately good at predicting genes associated with schizophrenia.
I found no significant performance differences from factoring in evidence levels.
Summer Week 7: Finalizations
Changed our SZ positives to be evidence based. The number of layers the positives are in is determined by the evidence level. It does better than before. We are confident in the gene lists and are looking into the candidate genes for experimental validation
Summer week 5
This week, there is a conference on campus for Galaxy and open source bioinformatics projects. Also, we’re refining the code.
Summer Week 4: Vacation
I was on vacation
Summer Week 3: Figures and papers
This week, we scrambled to make figures for the paper we are submitting to the conference. Mostly just writing and figure making.
Week 2: Sinksource+ and AUCs
We found an algorithm that solves the edge case problem. Sinksource+ removes the negatives and adds one negative to every single node. The weight of the edge is also a constant, which means that it’s the same for a node of any degree. This significantly devalues nodes that aren’t very well connected and would not be suitable for polygenic analysis.
However, it works horrendously in a single layer method with no prime nodes. The AUC sticks at around 0.5, which is the worst possible AUC you can have. However, it works great in a two layer network, giving our SZ network a score of 0.65. If you add negatives back in with the addition of sinksource+ and reduce the sinksource+ constant, we get an SZ AUC of 0.675 and a cell motility AUC of 0.801, which is the best AUC we have seen for an SZ gene identifier. I’m also running the program on the autism positives right now, and it appears that the AUC is running at about similar levels to where they were with E1 and E2.

Krishnan, A. et al.Genome-wide prediction and functional characterization of the genetic basis of autism spectrum disorder. Nature Neuroscience19,1454 (2016).
I think we are at the point where we will begin writing the paper. These results are a satisfying in that it’s probably just the nature of SZ that genes implicated are going to be difficult and somewhat disparately related. That’s not necessarily a bad thing. Polygenic positives are by definition only contributing slightly towards a disease. The strongest p-value for a SNP in an SZ GWAS has a frequency of 0.765 in SZ participants and a frequency of 0.75 in control participants. A low AUC in an SZ gene labeler is almost expected.
Goals for next week: Write the paper
Summer Week 1: Prime Nodes
This week, I got caught up with the state of the project. Anna and Miriam had cleaned up and optimized our code to the point where it could be submitted and run in a reasonable amount of time. However, there still remained the problem of nodes only connected to positives. Since positives are held at a constant score of 1.0, and negatives at a constant 0.0, any nodes only connected to a positive will have a score of 1.0, which misrepresents how a gene fits within the polygenic nature of schizophrenia and cell motility.
To solve this, we decided to make three networks, each one identical to the one we were previously testing. However, there are two key differences.
- The positives are divided between the three networks.
- The three nodes in each networks representing their gene are also connected to a prime node that is only connected to those three nodes. The prime node’s score is the node by which we judge a gene.
This reduces the edge cases where a gene is only connected to a positive or a negative, since the gene cannot be connected to only one node. This also allows us to evaluate positive nodes within the context of all other positives. If a positive node is found to be positive in other networks, then the score will be high. Even the neighbor positives within the same network will diffuse the positivity through their prime nodes down to other networks, increasing the score for the neighbor of the positive and therefore increasing the score for the positive.
One thing to note is that the AUC seems to be relatively stable despite the network threshold or the prime node implementation. However, my guess is that this is probably due to the positives generally being only vaguely functionally related. Also, only 116 SZ genes are in the 0.200 network, reducing the polygenic power of our method. One thing to try is to add more genes from other studies. I will research other studies to find more gene lists and p-values.
Week 23
I ran the bulk-BLASTer to find good homology targets from our results
Derek Applewhite, our cell biology advisor, noted that several top genes could be novel to flies, and several genes could be novel to cell motility.
Miriam and I will continue to work out the bugs in the verification system for our process.