
Most of what we are doing is not computational. We have been creating RNAi to inhibit our genes of interest. It’s tricky with drosophila: only a handful of the candidate genes are expressed in our cell line and only a subsection of that was capable of RNAi production. Despite this, we managed to produce 4 RNAi lines for these genes.
Category: Summer Research 2018
Week 10: Fixing Up Nodescoring
Anna and Ibrahim came up with two new ways to weight the nodes, both of which have produced a far greater range of nodeweights than the original nodescoring.py program did. The histograms for the new node weights are as below:
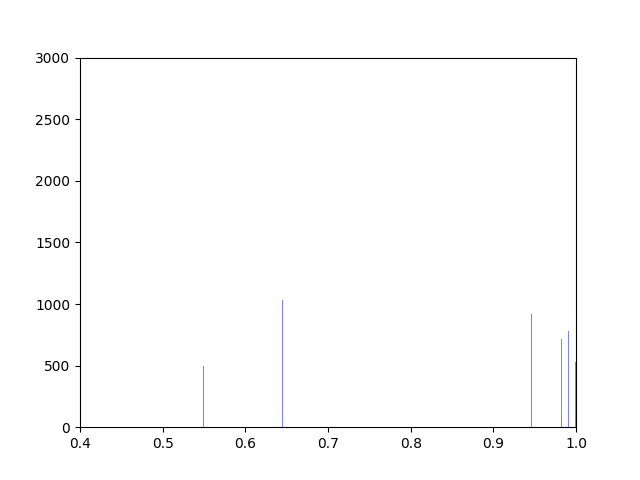
Beyond that, I have spent most of this week making small tweaks to nodescoring.py so that it runs more smoothly.
Week 9: Fixing Nodescoring.py
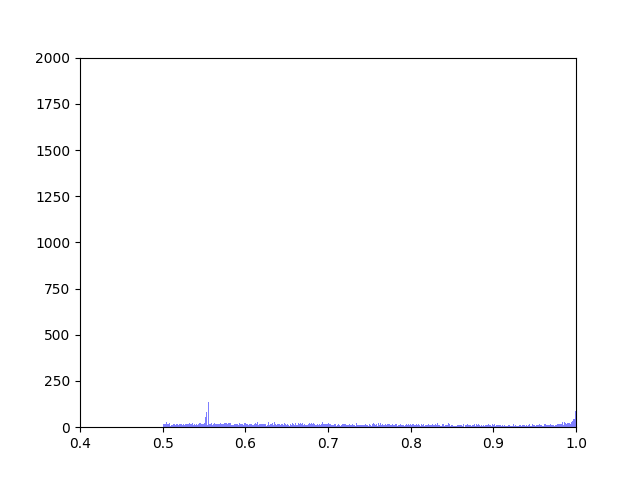
In my last blog post, I talked about how I was concerned about how small the range of normalized node scores is. This week I’ve been trying to figure out why that is. To do this I’ve been making histograms of each step of the process from foldchange to Xv to Cv. This is an example of that process for one gene:
The Cv of the gene above was 0.5000000003. Unfortunately, it looks like a lot of genes even with fairly different fold change and Xv distributions end up with very similar Cvs.
Ibrahim realized that this is occurring because there is an error in the equations we were using so we will have to rethink the way we normalize the data.
Week 9: Cell tracking
So now we are in the experimental validation phase. This week, we ran a trial run of the cell tracking software, using newly cultured cells from a drosophila melanogaster, or fruit fly, line. These lines are suitable for validating that the genes are involved in cell motility due to the high degree of conservation between humans and fruit flies in basic cellular mechanisms.
Week 7: Matrix Files
This week, I’ve been creating a tabular file with all TCGA-COAD samples at the top of the file as column names, with genes at the sides. I should have a 512 x 60484 matrix file when done. However, with Sol’s help I realized that the file I initially output was actually 512 samples at the top, with only 443 columns after, but still with 60484 lines to the file.
Therefore, I think there’s something wrong in how I’m categorizing/organizing the samples.
Week 8: Putting Everything Together
This week Kathy, Usman and I met to discuss how we would combine the projects we’ve been working on into a cohesive pathway and how we would analyze the output of CancerLinker as compared to PathLinker.
I have been working on ways to visualize the data. One thing I wanted to look at was how incorporating gene expression data would change the overall distribution of edge weights in the interactome.
The original interactome has a reasonable distribution with two values that seem to appear frequently around 0.4 and 0.8.
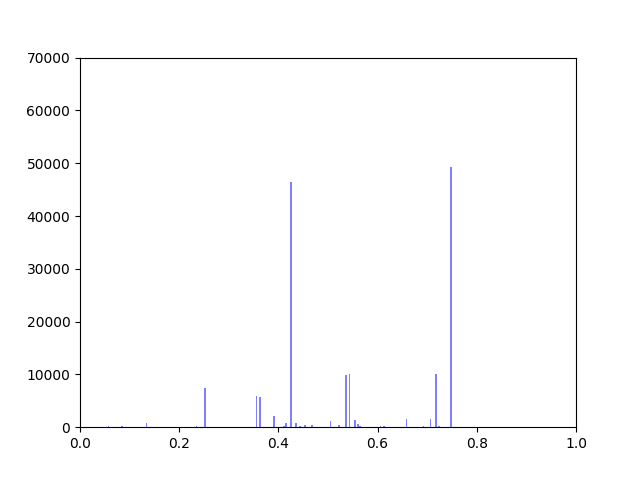
Gene expression data was incorporated into the original interactome with a beta value. The beta value determines the weight of the original edge weight when including the gene expression data. So the higher the beta score, the lower the importance of the gene expression data. I made three histograms one for a beta=0.25, one for beta = 0.5 (equal contribution between original edge weight and gene expression data) and one for 0.75
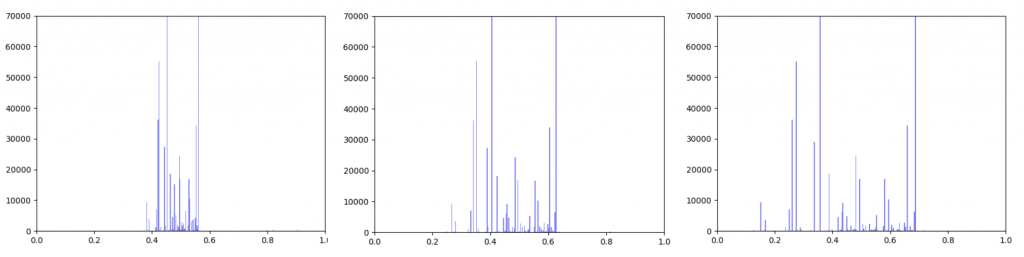
Left B=0.25, Middle B=0.5, Right B=0.75
As can be seen in the histograms above, when gene expression data is weighted more heavily, edges weights are more closely clustered. To investigate why this occurred I made two additional histograms: one of the gene expression data before it was transformed and one of the gene expression data after it was transformed.
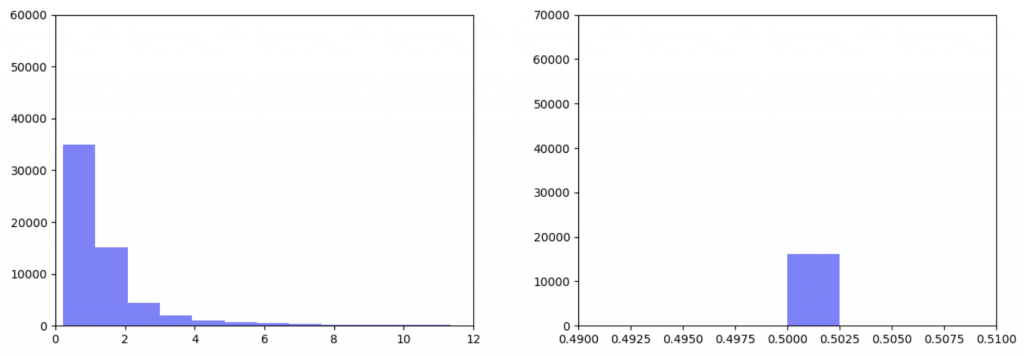
Right: Gene expression data after being transformed
After the gene expression data is transformed, there is extremely little variation. Additionally all the gene expression data is greater than or equal to 0.5 which should be the median. This would explain why weighting the gene expression data more heavily causes more closely-clustered edge weights. I’m not sure how to fix this. It seems like an error, but I’ve been over the code multiple times and the math seems right to me. So my next step is to figure out what’s going on there.
In the meantime I took the output from the pipeline that Kathy put together and put graphs for the top 1000 Wnt paths with β=0.25, 0.5 and 0.75 up on GraphSpace. If I figure out what’s wrong with the function that transforms the edgeweights, I will run it again and re-upload the updated graphs.
Summer Week 8: Positive and Negative Sets
I was curious about what our AUC would look like if instead of comparing hidden positives to unlabeled, we compared hidden positives to hidden negatives, wondering if that would get us a more valid representation of the network’s ability to predict genes associated with schizophrenia. What if the unlabeled genes ranked above the hidden positives were simply actual centers of genetic perturbations in schizophrenia?
Oddly enough, the scores actually decreased from 0.65-0.70 to 0.60-0.65. I found that the AUCs for comparing hidden negatives to unlabeled nodes hovered around 0.53, meaning that the hidden negatives were ranked mostly in the top half of the list.
This somewhat makes sense though. The basis for the negative set is that they are genes in non-neurological diseases, but that doesn’t necessarily exclude them from being included in a more subtle, polygenic disorder that’s dependent on additive effects of hundreds of genetic perturbations. It also makes sense that genes involved in other diseases might have a slightly higher probability of being associated with some other disease.
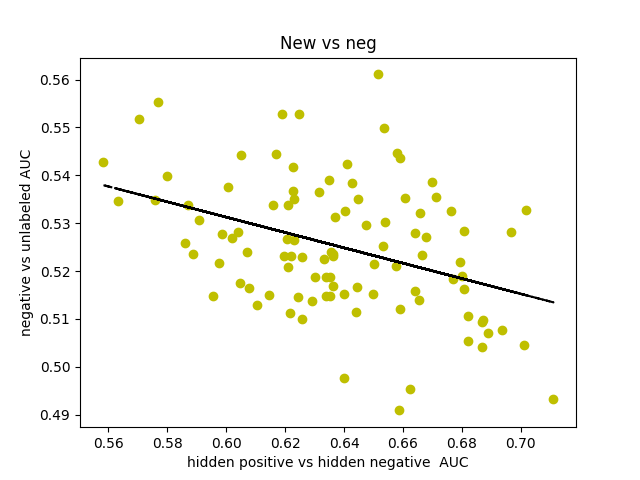
I decided to make a new negative set. I started by gathering every single node in the 0.150 network. There is a resource called SZGR 2.0 (https://bioinfo.uth.edu/SZGR/) that collects all sorts of evidence for genes being associated with schizophrenia. Using this list, I excluded any gene that had any evidence for being associated with schizophrenia. I then took differential gene expression data from autism spectrum disorder, bipolar disorder, and major depressive disorder as well as schizophrenia (http://science.sciencemag.org/content/359/6376/693). If a gene was not differentially expressed in any of these diseases (FDR>0.5 for schizophrenia, FDR>0.2 for others) and was in the other list, I added that gene to my list of negatives, which was 1561 genes long. I found that this list, when hidden negatives were compared to unlabeled genes, had an AUC of about 0.44, which means that our negatives are finally oriented around schizophrenia rather than non-neurological diseases. I also found that the AUC for hidden positives vs hidden negatives spiked up to 0.75, meaning that our program is legitimately good at predicting genes associated with schizophrenia.
I found no significant performance differences from factoring in evidence levels.
Pathlinker Interactome Weighting
This week I began to write code to weight the Pathlinker Interactome using the Bayesian Weighting Scheme. This will be useful to compare the HIPPIE and the Pathlinker Interactome but it also serves as a check to confirm whether the code accurately weights the interactomes. The Pathlinker Interactome was initially weighted using the same scheme and so the weights generated should match the pre-existing weights of the interactome. Next steps will involve comparing the two interactomes.
I spent some time writing code that allows conversion of a list of Uniprot IDs to the common name of the genes. This code will probably prove useful at some later point. I extended this to convert from Ensemble IDS to Uniprot IDs as well. However, the Ensemble and Uniprot databases do not entirely overlap and so there are some Ensemble IDs with no corresponding Uniprot IDs. I currently have no ideas about how to solve this problem but it does not appear to be one that needs to be urgently solved.
Week 7: Node Scoring
I have spent most of this week trying to transform the gene expression data and implement the equations that Ibrahim came up with to incorporate gene expression data onto edge scores.
I have had several major hold-ups to accomplishing this. The first is pretty simple, I just don’t know how to get the kind of data output I want from the CDF function because the scipy.norm.cdf() function outputs an array and I want a single value for each node.
The biggest issue is that the TCGA data on gene expression and PathLinker use different gene nomenclature systems. The TCGA relies on Ensembl IDs whereas PathLinker relies on UniProt IDs. Originally I tried to convert all the Ensembl IDs to common names to UniProt IDs because I have a file that contains UniProt IDs and common names, and another file that contains Ensembl IDs and common names. However, this didn’t work because a single gene may have multiple common names and may refer to multiple UniProt IDs (for example there are about 20 UniProt IDs that correspond to the HLA-A gene).
Therefore, to avoid the loss of data due to various common names, I tried to make a dictionary of Ensembl IDs directly to UniProt IDs. I was able to obtain a file that contained both UniProt and Ensembl IDs from the HUGO Gene Nomenclature Committee website. However, converting between Ensemble and UniProt came with its own problems. First of all, there are many genes that either only have UniProt IDs or only have Ensembl IDs. 997 genes in the interactome were unable to be converted from one to the other because of this reason. In addition, many of the Ensembl IDs in the TCGA file (over 16,000) don’t line up with any of the Ensembl IDs in the dictionary I constructed. I think this might be because the Ensembl IDs in the TCGA file include version numbers at the end of each ID. The version number is the decimal point at the end of the ID name. For example for the gene, “ENSG00000242268.2”, the “.2” means that this is the 2nd version of that gene. I think one way to fix this problem might be to just take all the version numbers out of the gene name when constructing the dictionary from the TCGA file. However, I can’t figure out how to do this without making the code super slow. If every version number were a single decimal place (ie: .1, .2, .3 … etc), I would just cut off the last two digits of each name which wouldn’t be that slow. However different IDs have different number of decimal places. For example, if I cut off the last two digits of “ENSG00000167578.15” I would still be left with the decimal point. Therefore the only way I can currently think of to get rid of the decimal and everything following it is to use a for-loop that goes through every character in the name and if the character is a decimal point to cut the string there. However, if the program has to go through every letter in every gene name, it’s going to be extremely slow. Maybe something I could do is pre-process the data to create a text file that contains gene IDs without the decimal places so it only has to do it one time and won’t slow the whole code down, but I feel like there has to be a faster way to do it within the program.
Summer Week 7: Finalizations
Changed our SZ positives to be evidence based. The number of layers the positives are in is determined by the evidence level. It does better than before. We are confident in the gene lists and are looking into the candidate genes for experimental validation